One of the potential solutions for tackling the problem of RF congestion is integrating sensing and communication infrastructures in a manner where they use the same frequency band in a controlled way. In our last paper, which is submitted to Journal of Selected Areas in Communications (JSAC), we have proposed a mechanism to perform multi-radar sensing in Cellular Networks via NR Sidelink (link to the ArxiV version). In this article I want to briefly discuss the idea and give some insights on collaborative sensing using multiple FMCW mmWave radars (the working principles of this type of radars are discussed in the previous post).
To begin with, let’s briefly discuss the sidelink capability which is recently introduced by 3GPP to reserve channel resources in the system. The LTE/NR sidelink feature (PC5 interface) has been introduced first in LTE releases 12 and 13 for device-to-device communication. Specifically, a user equipment (UE) device may request resources for sidelink communication from the corresponding gNB. According to the standard, the sidelink communication then occurs via the Physical Sidelink Shared Channel (PSSCH). In this work we utilize this functionality to perform sensing as shown in Fig.1. For more information about the sidelink implementation’s detail you can read our paper on ArxiV.
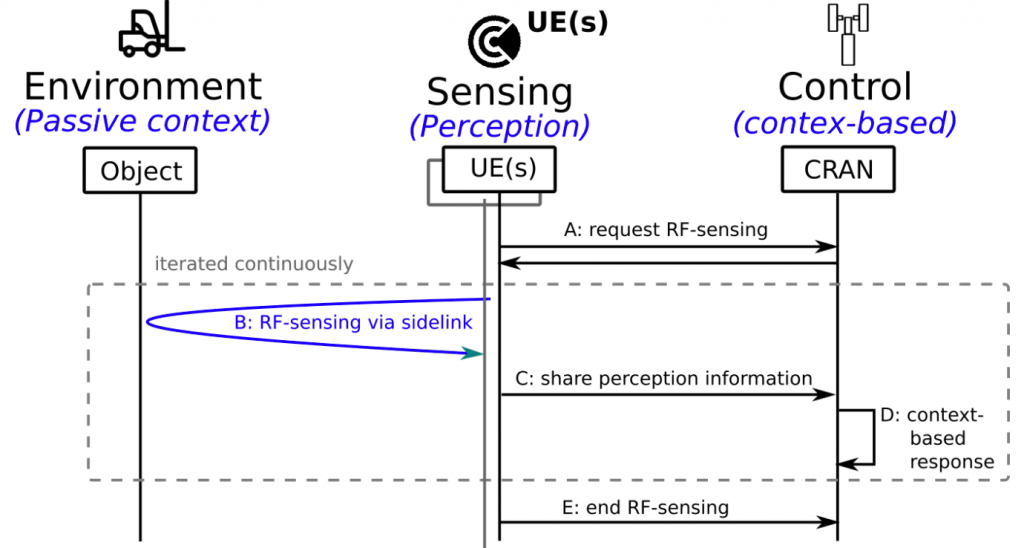
Now we assume that we already have a resource allocated by base-station to perform sensing. In this paper we use 8 radars simultaneously to sense the environment from 8 different angles. First, the relative orientation of the RF-interface and the subject (e.g. in gesture sensing) or (moving) object (e.g. environmental perception) significantly impacts the observed electromagnetic pattern and hence the recognition accuracy. Second, we can combat shadowing effect that happens when the area of interest is shadowed or even completely blocked in the environment. We demonstrate this impact in an experimental study with 15 subjects and more than 25,000 data samples.
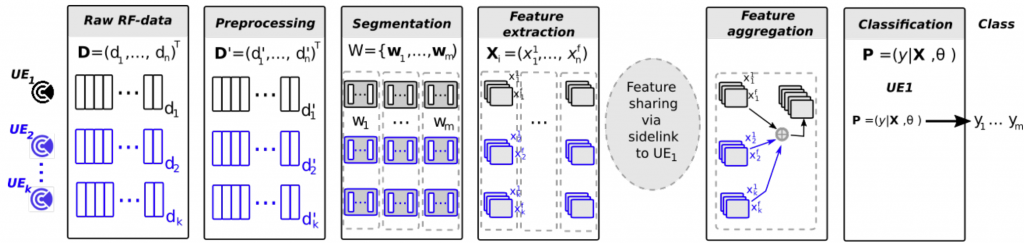
Fig. 2 shows the data processing pipeline for collaborative sensing in NR Sidelink. Each UE (in this case FMCW mmWave radar) performs independent sensing in the reserved resource, then they apply pre-processing, segmentation and feature extraction steps, and finally using communication capabilities they share the features to identify the correct label of the gesture performed by the participant in the environment. In this work we study gesture recognition scenario using the proposed mechanism. Although using multiple NR sidelink-based radars for sensing the environment can potentially address the shadowing effect and the low-resolution of the radar in z-axis, it also gives rise to issues due to the interference between radars including noise floor degradation, blind-spots at certain ranges or directions, as well as ghost objects. How do we address this problem?
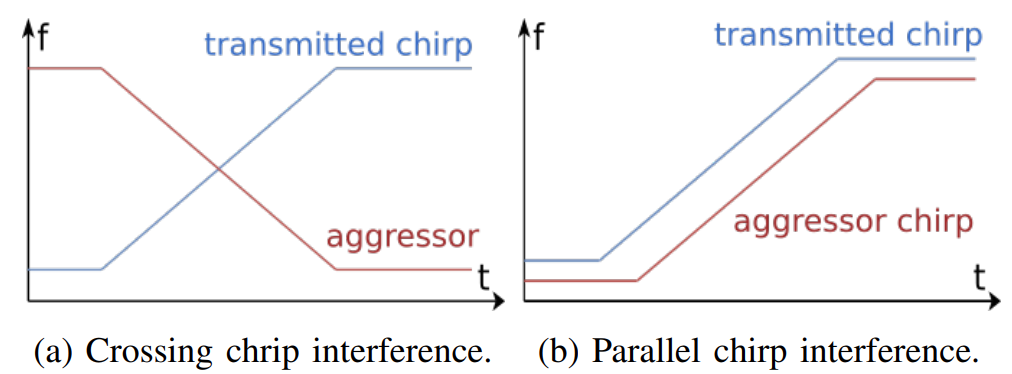
Two different types of interference can occur with FMCW radars: crossing chirp interference and parallel chirp interference. As shown in Fig. 3.a, crossing interference occurs when one chirp (referred to as aggressor in the following) crosses the chirp of another chirp (referred to as victim, since it is falling victim to the interference of the aggressor). This type of interference typically increases the noise floor resulting in a reduction in Signal to Noise Ratio (SNR) of the real targets thereby affecting detection and creating momentary blind-spots. The glitch duration in crossing interference is given by:

According to Equation 1, the glitch duration for two crossing interferers is typically low and affects few samples. The parallel interference is shown in Fig. 3.b. This type of interference occurs when the aggressor chirp and the victim chirp have the same slope. If the delay in the start of a chirp between different radars is within microsecond, the aggressor chirp will be within the bandwidth of the entire chirp of the victim. This type of interference results in ghost objects at random distance with random velocity that do not exist in the environment but are detected by the radar. Since such interference will occur only when the NR sidelink operating radars start nearly simultaneously, the probability of it is small. During the experiments we employed the built-in capability of the radar in interference detection to avoid any interference issues in the recorded dataset.
Now, let’s go to the actual gesture recognition model we introduced in the paper to recognize gestures performed by participant using 8 radars. To do so we introduced two different approaches: orientation independent and orientation tracking shown in Fig. 4. The main difference is that in orientation tracking for each angle we have a separate feature extraction learners while in orientation independent we have a single feature extractor for all the angles.

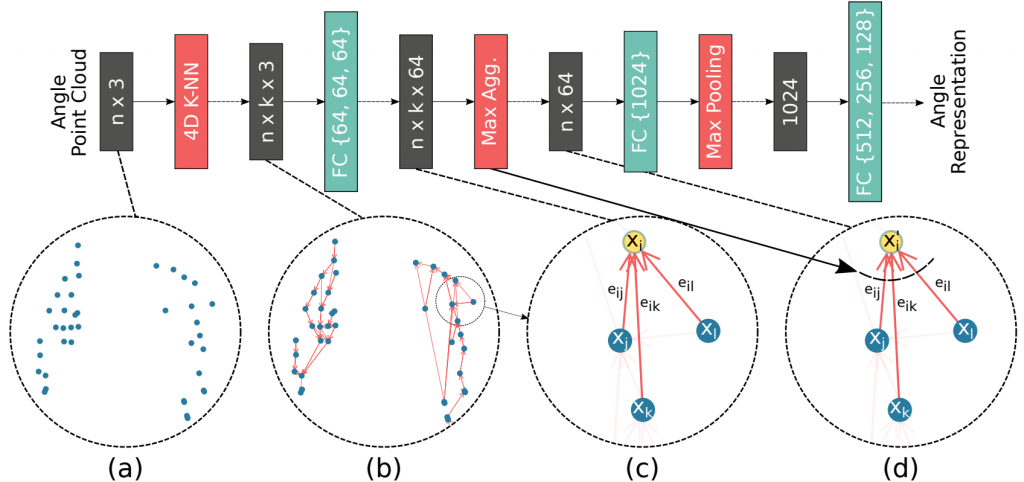
What is the encoder block in Fig. 4? The radar we use in this work is IWR1443 by Texas Instrument (TI). A pre-processing pipeline is applied on I/Q data to generate point clouds. Consequently, the encoder block shown in Fig. 4 takes in 4D point clouds and produces a representation vector. The architecture of the graph-based encoder implemented using Message Passing Neural Network (MPNN) paradigm is shown in Fig. 5.
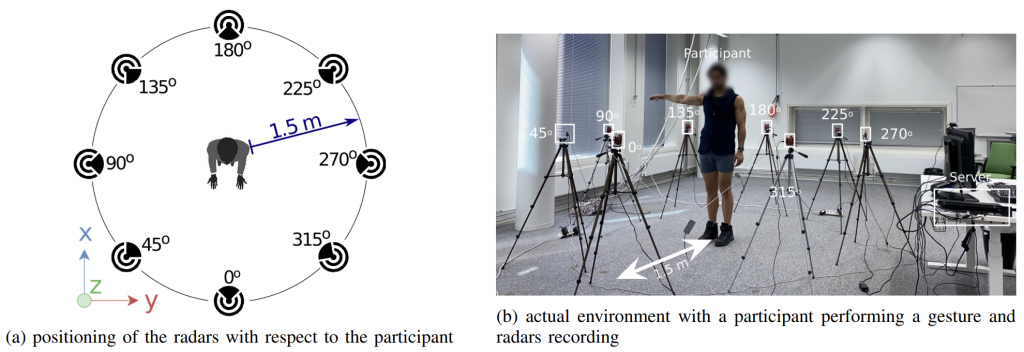
In Fig.4 for pooling purposes we propose four different mechanisms: max pool, vote pool, attention pool, and orientation tracking which are discussed in the paper. Now, it is time to briefly discuss the experiment setting. The experimental setup is shown in Fig. 6. As you can see we have eight different radars equally spaced on a circle around the participant with a distance of 1.5 m. The participant always faces the radar labeled 0o. We collected 10 repetition from each of the 21 classes of gestures of 15 participants from 8 different angles.
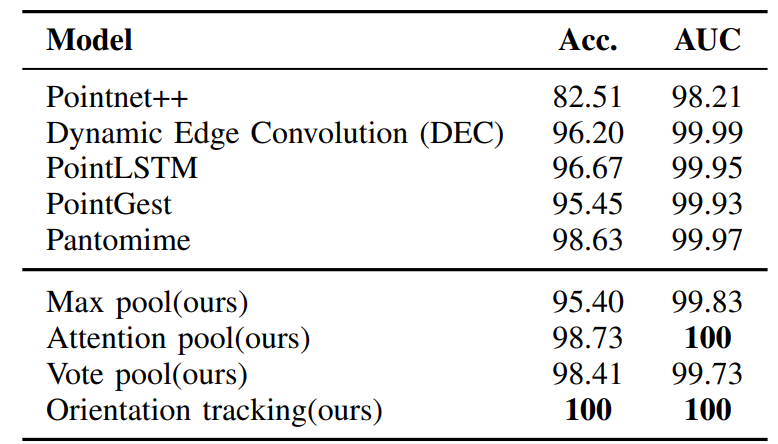
As shown in Table 1, two of our proposed models (attention pooling and orientation tracking) outperform state of the art. Especially the orientation tracking approach achieves 100% accuracy. In this experiment we assumed all of the 8 different angles are available in the training and inference phases.
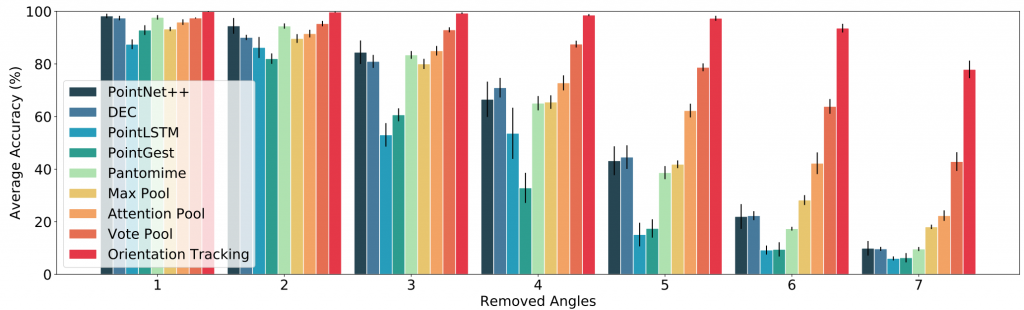
In another experiment we studied the effect of having less than 8 angles in the inference phase. So, the models are trained on 8 angles but inferred on less than 8 angles. As shown in Fig. 7, as we remove more angles the accuracy drops for all the models. But the drop for most of the models is dramatic. For example, in case of PointLSTM and PointGest the accuracy drops from 98% to almost 10% when we have only a single angle available in the inference phase. However, for our best-performing model, orientation tracking, the accuracy is around 80% even for a single angle.
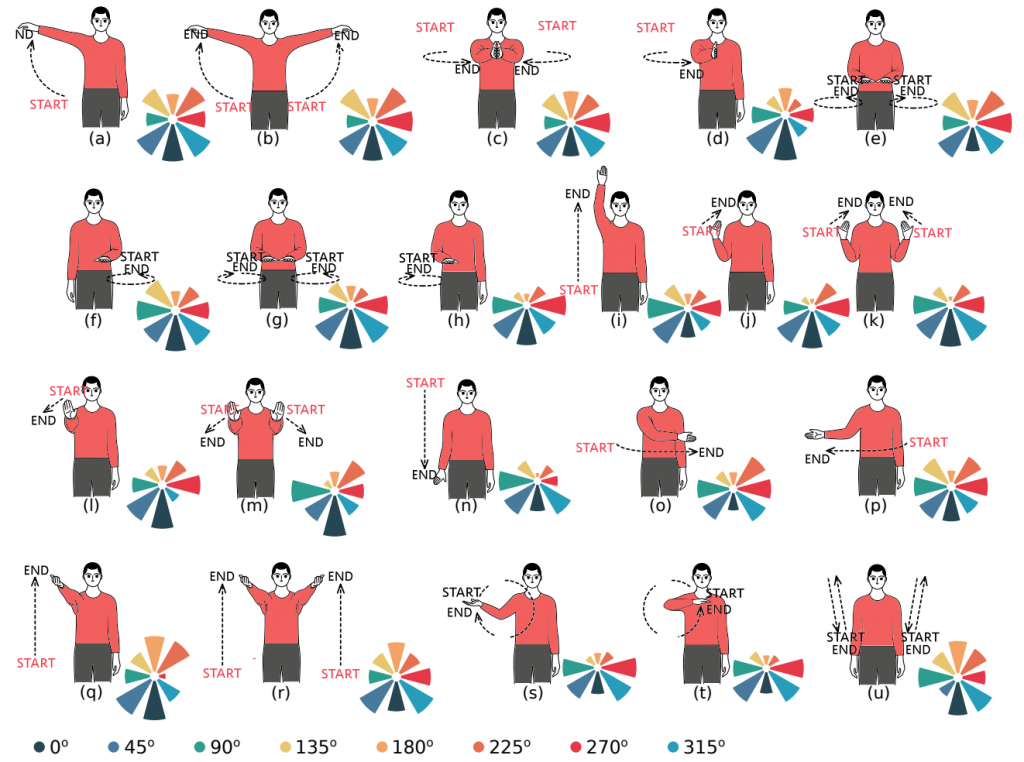
In Fig. 8, the importance of each angle for each gesture in the orientation tracking approach is shown in a polar chart. For most gestures the radars in front (0 ◦ , 45◦ , and 315◦ ) have the highest impact, while the radar at the back (180◦ ) has the least importance. However, for few gestures like (q), (r), and (u) where the hands are visible from a back view, the impact of the radar at 180◦ increases. Moreover, for the gestures that happen on one side of the body, e.g., (d) and (n), the radars on the same side are of higher importance compared to the radars on the other side.
In conclusion, we have proposed a mechanism for RF-convergence in cellular communication systems. In particular, we suggest to integrate RF-sensing with NR sidelink device-to-device communication, which is since the release of 12 part of the 3GPP cellular communication standards. We specifically investigated a common issue related to NR sidelink based RF-sensing, which is its angle and rotation dependence. In particular, we discussed transformations of mmWave point-cloud data which achieve rotational invariance as well as distributed processing based on such rotational invariant inputs at distributed angle and distance diverse devices. Further, and to process the distributed data, we proposed a graph based encoder to capture spatio-temporal features of the data as well as four approaches for multi-angle learning. The approaches are compared on a newly recorded and openly available dataset comprising 15 subjects, performing 21 gestures which are recorded from 8 angles. We were able to show that our data aggregation and processing tool chain outperforms the state-of-the-art point cloud based gesture recognition approaches for angle-diverse gesture recordings.