Introduction
In this post, we are going to discuss the pattern recognition from spatial data in motion through a zero-shot learning scenario. We use Siamese networks architecture to recognize unseen classes of motion patterns. A graph-based approach is adopted to achieve permutation invariance and encode moving point clouds into a representation in a computationally efficient way.
Point-clouds are acquired from mmWave Radars, RGB-D cameras, or LiDARs. They constitute unstructured sets of points, often in a three-dimensional space. Unlike pixels in images, points in point-clouds can substitute each other without changing the underlying semantic representation, which poses challenges for processing them. In this work, we process point-clouds acquired from mmWave Radars to recognize unseen classes of gestures.
Siamese Network
A Siamese neural network is an architecture with multiple identical encoder components  , each of which is responsible for calculating a latent space representation
, each of which is responsible for calculating a latent space representation  for an input sample
for an input sample  . The encoders have the exact same architecture, and weights and are updated simultaneously during the training phase.
. The encoders have the exact same architecture, and weights and are updated simultaneously during the training phase.
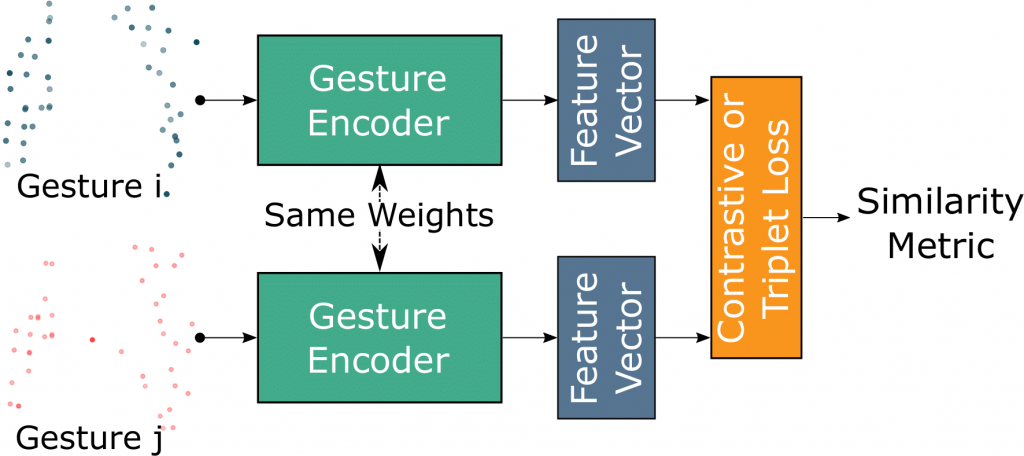
An overall structure of a Siamese network is shown in figure above. Since a siamese network is trained to separate dissimilar pairs in the latent space, it learns discriminative features which can be exploited to realize zero-shot learning. The output is a similarity metric, which is also computed for pairs of samples from a distribution that is unknown to the model. Contrastive loss and triplet loss are the loss functions that are often used to train Siamese networks.
Contrastive Loss
Contrastive loss  is a Euclidean-based similarity metric.
is a Euclidean-based similarity metric.

Here,  determines whether the gestures
determines whether the gestures  and
and  belong to the same class (
belong to the same class ( ) or not (
) or not ( );
);  is the Euclidean distance between the encoded representations of gestures and .
is the Euclidean distance between the encoded representations of gestures and .  is a margin to prevent the trivial solution with
is a margin to prevent the trivial solution with  , by configuring the hidden representations for all gestures onto a single point.
, by configuring the hidden representations for all gestures onto a single point.
Triplet Loss
Triplet loss minimizes the distance between an anchor gesture and a positive (same class), while increasing the distance to a negative (different class) gesture.

 is the encoded anchor gesture,
is the encoded anchor gesture,  is the encoded positive gesture,
is the encoded positive gesture,  is the encoded negative gesture, and is the margin to prevent a trivial solution.
is the encoded negative gesture, and is the margin to prevent a trivial solution.
Point-cloud Encoder
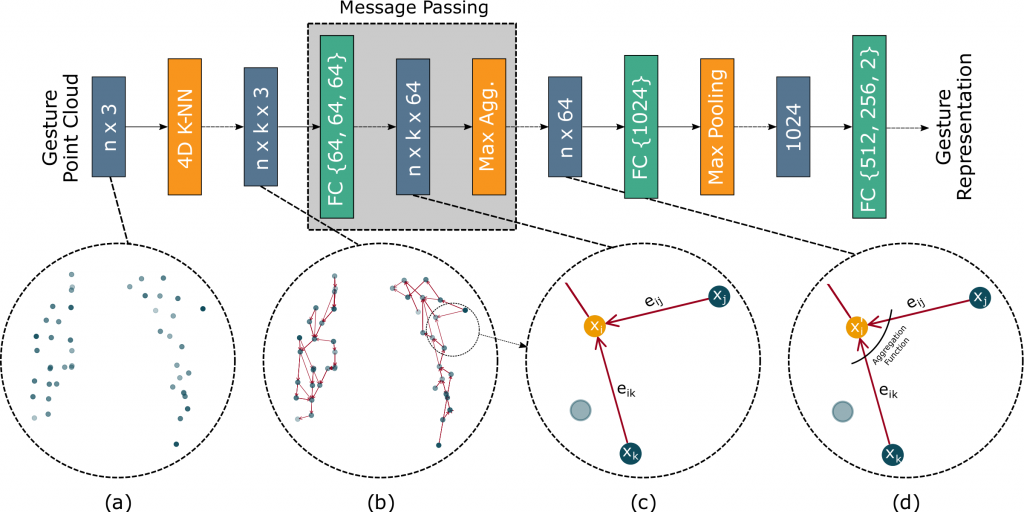
To encode the moving point-cloud into a latent space, we take advantage of Message Passing Neural Network (MPNN). First, we apply a temporal graph K-NN algorithm to build a graph from the input point-cloud. In this process, we connect each point to its nearest neighbors from next time frames. In the second stage, we build edge features. Finally, the updated representation of each node is calculated by applying a pooling function over the edge features of the edges incidenting at the node. The schematic view of the method and the architecture of the model are shown in the figure below.
Results
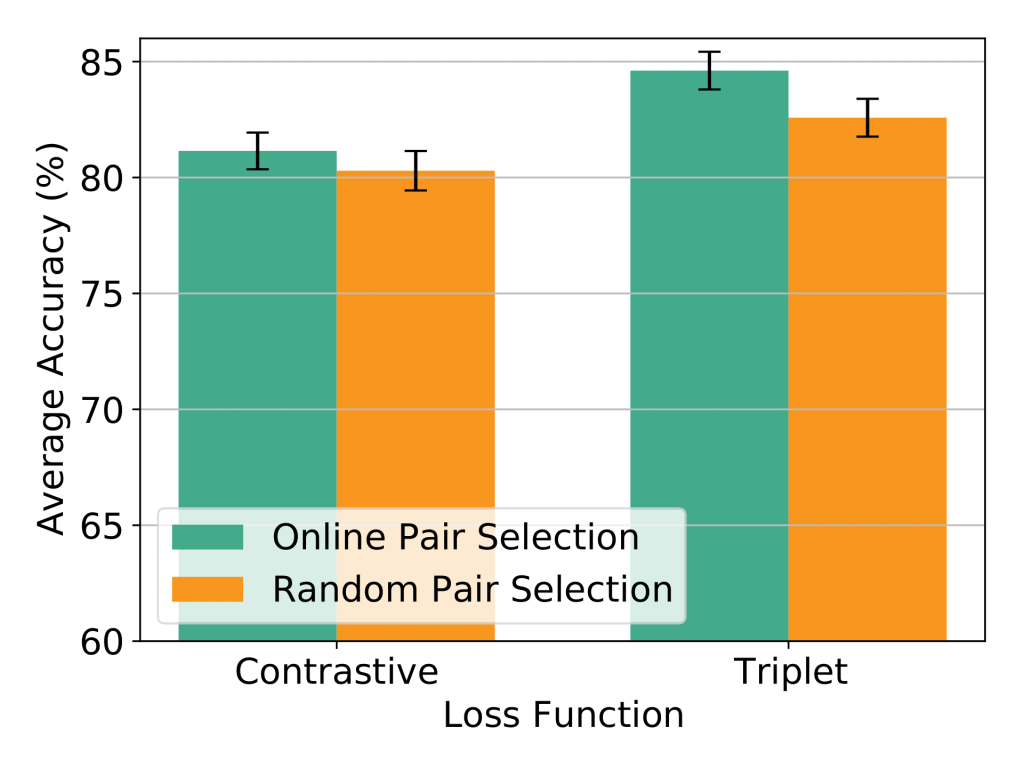
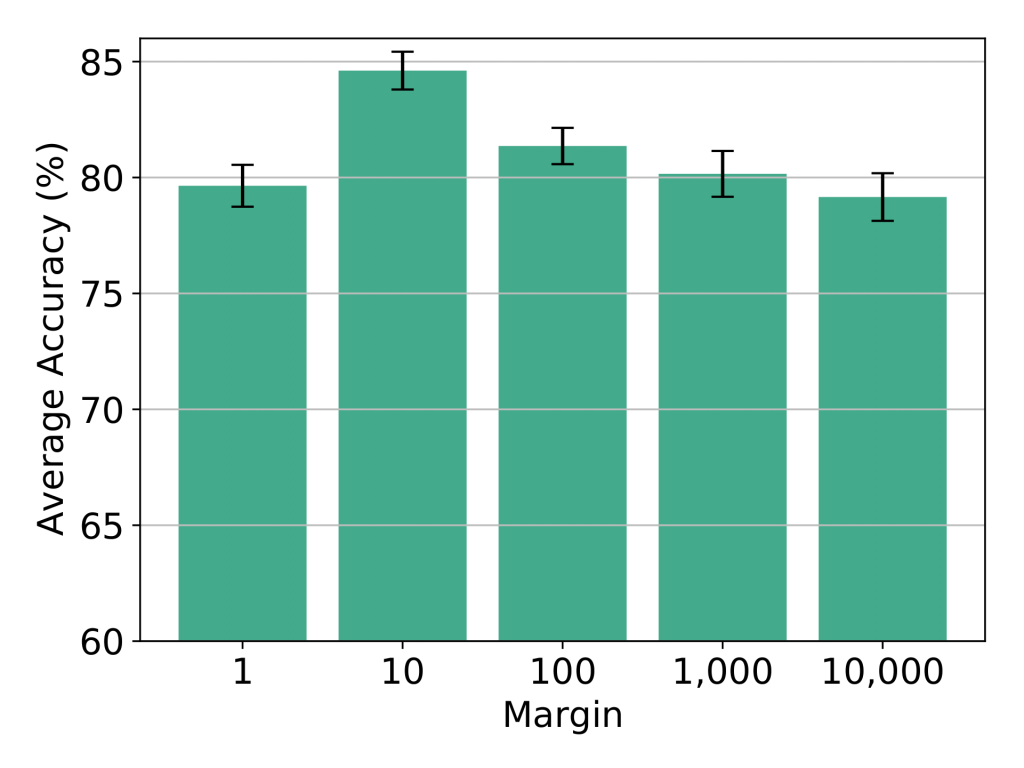
In this section, we discussed the results of our work. In the figure below we have results for different loss functions with different pair selection strategies. As you can see, Triplet loss with online pair selection approach performs the best. On the other hand, in the right figure, the effect of different margin values is shown. When margin is 10, we have the best results for Triplet loss with online pair selection mechanism.
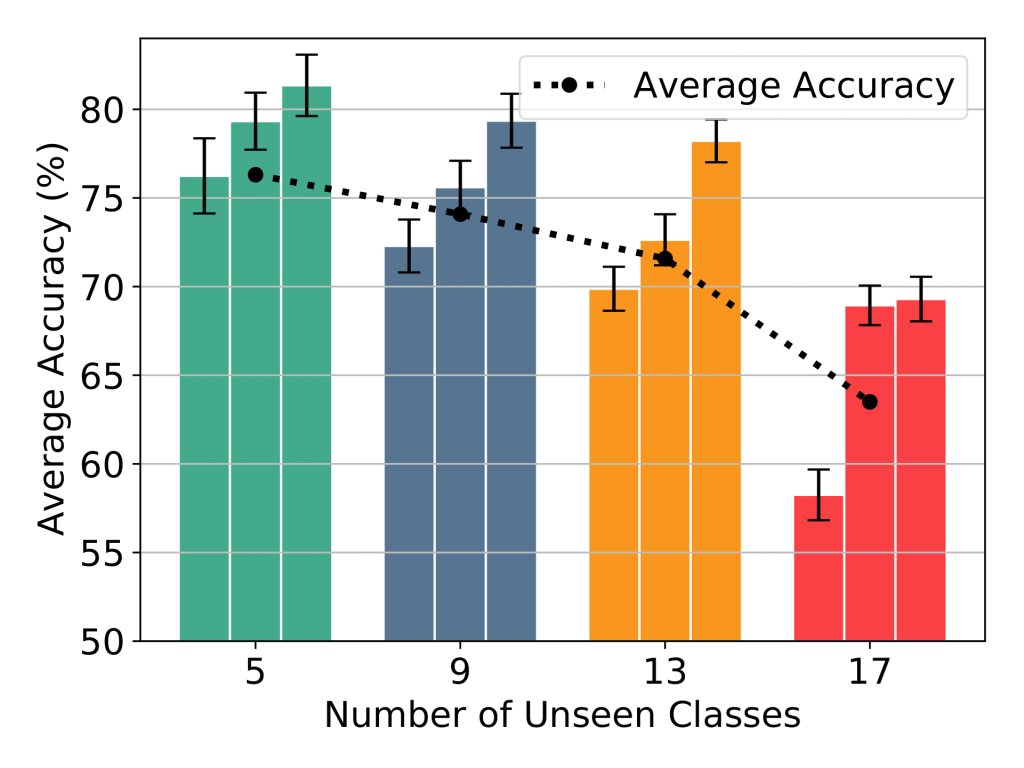
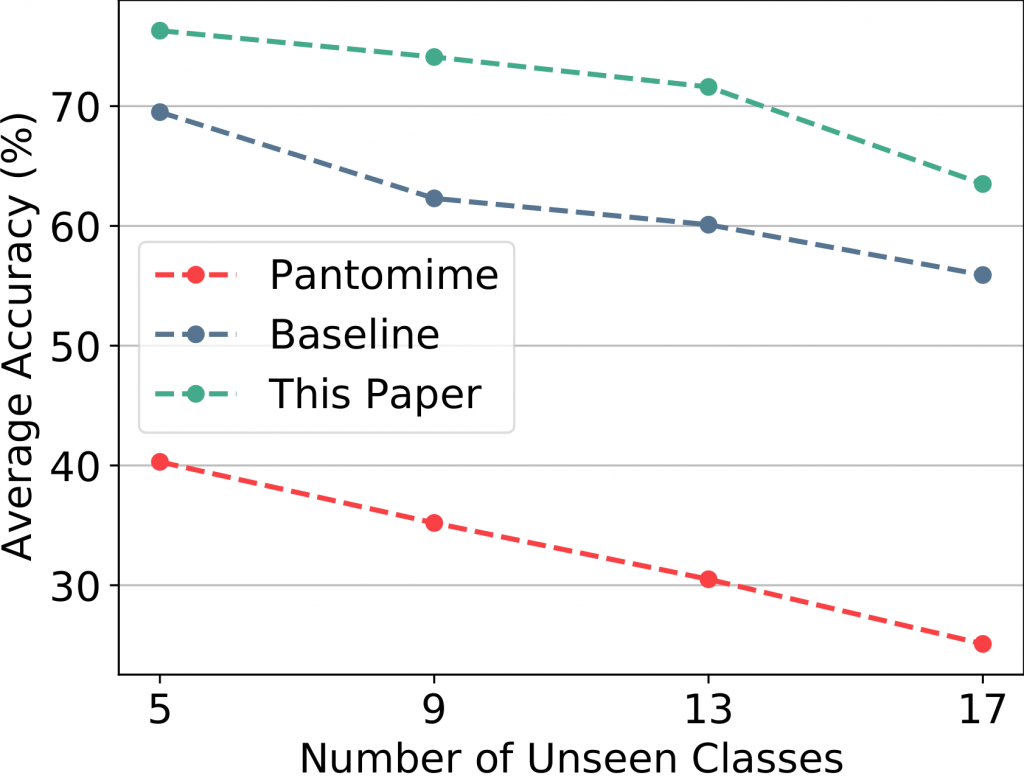
Moreover, in the figure below on the left side, we can observe the effect of different number of unseen classes on the accuracy of the model. As we increase the number of unseen classes, the accuracy decreases. Furthermore, on the right side we have compared our model to baseline and also Pantomime model. As we can see, our proposed method outperforms state of the art by a considerable margin.
Conclusion
We have introduced our work on a neural network architecture for zero-shot motion recognition from 4D point clouds which is published in MLSP 2021 (full publication). We showed that our model outperforms state-of-the-art with a considerable margin in terms of average accuracy of un-seen classes of gestures. We also discussed different loss functions, training schemes, unseen scenarios, and margin values through a set of extensive experiments.