This article aims to introduce and clarify kernel ridge regression. To do so, it is necessary to derive a simple formula: the orthogonal projection formula. The reason is that, to understand kernel ridge regression, we need to understand how linear regression works, but the whole theory of linear regression relies on the solution of the following question: what is the projection of a vector  on a vector
on a vector  .
.
Projection of vector on vector
First, let’s consider simple case of projection vector on vector in -dimensional Euclidean space. Figure
1. Illustrates this scenario. Vector we want to find is
-dimensional Euclidean space. Figure
1. Illustrates this scenario. Vector we want to find is  , which is the projection of on .
, which is the projection of on .
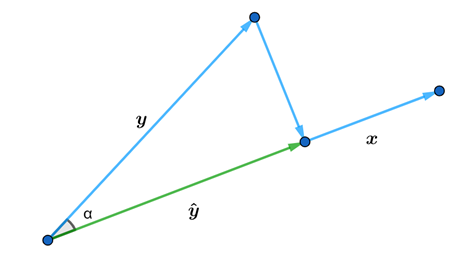
First of all, notice that the projection vector is just a “rescaled version” of the vector , that is 
 . How much we should “rescale” depends on two things: (i) How long the vectors and are. (ii) Most importantly mutual arrangement of the vectors and ! Both of the points above can be formalized by the notion of scalar product (central object of this article). In Euclidean space scalar product is defined as follows (you may recognize the low of cosines)
. How much we should “rescale” depends on two things: (i) How long the vectors and are. (ii) Most importantly mutual arrangement of the vectors and ! Both of the points above can be formalized by the notion of scalar product (central object of this article). In Euclidean space scalar product is defined as follows (you may recognize the low of cosines)
![\[\langle\boldsymbol{x}, \boldsymbol{y}\rangle=\|\boldsymbol{x}\|\|\boldsymbol{y}\| \cos \alpha\]](https://ksp-windmill-itn.eu/wp-content/ql-cache/quicklatex.com-f0b124f55a5cf3b7e768b5a8d353e250_l3.png "Rendered by QuickLaTeX.com")
and are orthogonal to each other or (2) they have the same direction. In the first case, the scalar product is zero since  . For the second case, scalar product achieves the maximum value, which is the product of the length of vectors.
Problem 1. How is this fact related to the Cauchy-Schwarz inequality?
. For the second case, scalar product achieves the maximum value, which is the product of the length of vectors.
Problem 1. How is this fact related to the Cauchy-Schwarz inequality?
Problem 2. Denoting by
 and Y random vectors with realizations and correspondingly, what is the relationship between sample correlation of and and the formula
and Y random vectors with realizations and correspondingly, what is the relationship between sample correlation of and and the formula
![\[\frac{\langle\boldsymbol{x}, \boldsymbol{y}\rangle}{\|\boldsymbol{x}\|\|\boldsymbol{y}\|}=\cos \alpha .\]](https://ksp-windmill-itn.eu/wp-content/ql-cache/quicklatex.com-f379b1b41e15b8287085e77ccafb21f4_l3.png "Rendered by QuickLaTeX.com")
 in
in  . Notice that dividing by
. Notice that dividing by  gives us the vector
gives us the vector  with the same direction and the length 1 (this procedure called normalization). If we replace with in then the problem of finding is equivalent to the problem of finding the length of , so
with the same direction and the length 1 (this procedure called normalization). If we replace with in then the problem of finding is equivalent to the problem of finding the length of , so  By the definition of
By the definition of  we have
we have 
 , using the formula from Problem 2 gives us
, using the formula from Problem 2 gives us  .
.
![\[\hat{\boldsymbol{y}}=\frac{\langle \boldsymbol{x}, \boldsymbol{y}\rangle}{\|\boldsymbol{x}\|^{2}} x=\frac{\langle \boldsymbol{x}, \boldsymbol{y}\rangle}{\langle \boldsymbol{x}, \boldsymbol{x}\rangle^{2}} \boldsymbol{x}\]](https://ksp-windmill-itn.eu/wp-content/ql-cache/quicklatex.com-3105568a5293d473e1e5abb67c577c83_l3.png "Rendered by QuickLaTeX.com")
 has the length one, the formula above can be simplified as follows
has the length one, the formula above can be simplified as follows
![\[\widehat{\boldsymbol{y}}=\langle\boldsymbol{x}, \boldsymbol{y}\rangle \boldsymbol{x} .\]](https://ksp-windmill-itn.eu/wp-content/ql-cache/quicklatex.com-94bab4556f53ff6714a50cea15b5775f_l3.png "Rendered by QuickLaTeX.com")
 by
by  , so the
, so the  operation does the projection of any vector to the given vector of unit length. Now observe that the operation is linear in the second argument
operation does the projection of any vector to the given vector of unit length. Now observe that the operation is linear in the second argument
![\[\boldsymbol{x} *\left(a_{1} \boldsymbol{y}_{1}+a_{2} \boldsymbol{y}_{2}\right)=a_{1} \boldsymbol{x} * \boldsymbol{y}_{1}+a_{2} \boldsymbol{x} * \boldsymbol{y}_{2}\]](https://ksp-windmill-itn.eu/wp-content/ql-cache/quicklatex.com-770a2801b5e781058f0c5ad6a616d8a9_l3.png "Rendered by QuickLaTeX.com")
 , called projection matrix such that
, called projection matrix such that
![\[\boldsymbol{x} * \boldsymbol{y}=P \boldsymbol{y}\]](https://ksp-windmill-itn.eu/wp-content/ql-cache/quicklatex.com-0ed02cbacd3b1cc0b5598f43587a0cdb_l3.png "Rendered by QuickLaTeX.com")
is nothing more than  (Hint:
(Hint:  .)
.)
Problem 4. Show that
 , where
, where 
To summarize, matrix
 acting on the vector projects it onto the unit length vector . For general we have to normalize it by its length
acting on the vector projects it onto the unit length vector . For general we have to normalize it by its length  , so
, so
![\[P=\left(\boldsymbol{x}^{T} \boldsymbol{x}\right)^{-1} \boldsymbol{x} \boldsymbol{x}^{T}=\boldsymbol{x}\left(\boldsymbol{x}^{T} \boldsymbol{x}\right)^{-1} \boldsymbol{x}^{T} .\]](https://ksp-windmill-itn.eu/wp-content/ql-cache/quicklatex.com-f84940ad7a06827347937065480493ad_l3.png "Rendered by QuickLaTeX.com")
![\[P \boldsymbol{y}=\sum_{i=1}^{n} y_{i}\left(x_{i} x_{k}\right), \quad k=1, \ldots n\]](https://ksp-windmill-itn.eu/wp-content/ql-cache/quicklatex.com-c3a4531b76cd294b513784ac60202206_l3.png "Rendered by QuickLaTeX.com")
 .
.
Projection of vector on space
What about more general scenario when we want to project not on the one vector, but on the space  spanned by bunch of vectors
spanned by bunch of vectors  Figure
Figure  Illustrates this scenario when
Illustrates this scenario when  and space is three-dimensional.
and space is three-dimensional.
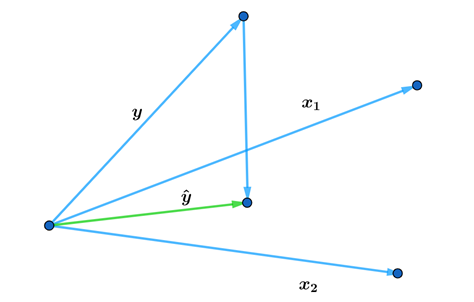 with matrix
with matrix  whose columns are the vectors spanning the subspace we want to project on
whose columns are the vectors spanning the subspace we want to project on
![\[P=X\left(X^{T} X\right)^{-1} X^{T}\]](https://ksp-windmill-itn.eu/wp-content/ql-cache/quicklatex.com-f6a6615ecdb4acf90c8204181057cc20_l3.png "Rendered by QuickLaTeX.com")
 , then
, then  and
and
![\[P \boldsymbol{y}=X X^{T} \boldsymbol{y}=\sum_{i=1}^{d} \boldsymbol{x}_{i} * \boldsymbol{y}\]](https://ksp-windmill-itn.eu/wp-content/ql-cache/quicklatex.com-9221a1e5de132bc0ccc3f3bca041185c_l3.png "Rendered by QuickLaTeX.com")
Problem 5. What does it mean in terms of linear regression? (Hint: In linear regression vectors
 are inputs (features), orthogonality just means that they are uncorrelated. When the inputs are uncorrelated, they have no effect on each other’s parameter estimates in the model.)
are inputs (features), orthogonality just means that they are uncorrelated. When the inputs are uncorrelated, they have no effect on each other’s parameter estimates in the model.)
As was discussed for one vector case, the projection is just rescaled (reweighted) version of the vector where we are projecting, with the weight given by a scalar
 . Same is true for the projection on the space spanned by multiple vectors, what changes is that we have to reweight each
. Same is true for the projection on the space spanned by multiple vectors, what changes is that we have to reweight each  according to the
according to the  component of the weighting vector
component of the weighting vector  . It means that
. It means that
![\[\hat{\boldsymbol{y}}=P \boldsymbol{y}=\sum_{i=1}^{d} \omega_{i} \boldsymbol{x}_{\boldsymbol{i}} .\]](https://ksp-windmill-itn.eu/wp-content/ql-cache/quicklatex.com-f144314d34016950edcc4bdc98befa6c_l3.png "Rendered by QuickLaTeX.com")
into always exists whenever  . In general case it can happen that
. In general case it can happen that  for all
for all  , but
, but  may not be defined.
may not be defined.
Problem 6. When does it happen?
This problem can be solved easily by adding a positive constant to the diagonal of
 before inversion. Even if is not invertible
before inversion. Even if is not invertible  is well defined for
is well defined for  . Procedure just described is known as Tikhonov regularization in literature. This motivates us to define regularized projection matrix
. Procedure just described is known as Tikhonov regularization in literature. This motivates us to define regularized projection matrix
![\[P_{\lambda}=X\left(X^{T} X+\lambda I\right)^{-1} X^{T}\]](https://ksp-windmill-itn.eu/wp-content/ql-cache/quicklatex.com-176036a144a2b226606d4eb92461a6c8_l3.png "Rendered by QuickLaTeX.com")
(1) 
 .
\section{Kernel ridge regression}
Now it’s time to talk about kernel ridge regression. To do so it’s more natural to talk about rows (observations) of the matrix rather then columns. Let’s denote them by
.
\section{Kernel ridge regression}
Now it’s time to talk about kernel ridge regression. To do so it’s more natural to talk about rows (observations) of the matrix rather then columns. Let’s denote them by  , so
, so  . First we need to rewrite identity (1) in terms of row vectors of . To do so we need the following identity
. First we need to rewrite identity (1) in terms of row vectors of . To do so we need the following identity
![\[\left(X^{T} X+\lambda I\right)^{-1} X^{T}=X^{T}\left(X X^{T}+\lambda I\right)^{-1}\]](https://ksp-windmill-itn.eu/wp-content/ql-cache/quicklatex.com-5063f680b0f95b15b8d572f6e54e86b8_l3.png "Rendered by QuickLaTeX.com")
Problem 7. Show that the identity above is true. Hint:
 .
.
Using this identity, we can write
![\[P_{\lambda} \boldsymbol{y}=X X^{T}\left(X X^{T}+\lambda I\right)^{-1} \boldsymbol{y}=\sum_{i=1}^{n} \alpha_{i}\left\langle\mathbf{x}_{i}, \mathbf{x}_{k}\right\rangle, k=1, \ldots, n\]](https://ksp-windmill-itn.eu/wp-content/ql-cache/quicklatex.com-86de6630ef67411c9ed2bbb017f67a08_l3.png "Rendered by QuickLaTeX.com")
 As one can see, to calculate projection you only need to know scalar product of the observations. It means that all you need to know is similarity measure of two input observations. In the derivation above we used ordinary scalar product for that. Main idea behind kernel ridge regression (and other kernel based methods SVM, GP,… ) is to replace the scalar product everywhere in the representation above by the scalar product of the form
As one can see, to calculate projection you only need to know scalar product of the observations. It means that all you need to know is similarity measure of two input observations. In the derivation above we used ordinary scalar product for that. Main idea behind kernel ridge regression (and other kernel based methods SVM, GP,… ) is to replace the scalar product everywhere in the representation above by the scalar product of the form
![\[K\left(\mathbf{x}_{i}, \mathbf{x}_{k}\right)\]](https://ksp-windmill-itn.eu/wp-content/ql-cache/quicklatex.com-f10a47841da23ef86e0f11fa3361d049_l3.png "Rendered by QuickLaTeX.com")
 is some symmetric, positive definite function called \textit{kernel}. For instance, the kernel
is some symmetric, positive definite function called \textit{kernel}. For instance, the kernel
![\[K\left(\mathbf{x}_{i}, \mathbf{x}_{k}\right)=\left\langle\mathbf{x}_{i}, \mathbf{x}_{k}\right\rangle\]](https://ksp-windmill-itn.eu/wp-content/ql-cache/quicklatex.com-ae5170152ab45255a4c63a17b75fb29f_l3.png "Rendered by QuickLaTeX.com")
![\[K\left(\mathbf{x}_{i}, \mathbf{x}_{k}\right)=\left(\left\langle\mathbf{x}_{i}, \mathbf{x}_{k}\right\rangle+1\right)^{m}\]](https://ksp-windmill-itn.eu/wp-content/ql-cache/quicklatex.com-95506ee5a6c303e5afbb4483156e3dce_l3.png "Rendered by QuickLaTeX.com")
![\[K\left(\mathbf{x}_{i}, \mathbf{x}_{k}\right)=e^{-\gamma|| \mathbf{x}_{i}-\mathbf{x}_{k} \|^{2}} .\]](https://ksp-windmill-itn.eu/wp-content/ql-cache/quicklatex.com-4b6c425c039b12579b1c4e5aadbf41e0_l3.png "Rendered by QuickLaTeX.com")