In this post we will discuss how can we allow medium access control (MAC) protocols to emerge with multi-agent reinforcement learning (MARL). Current MAC protocols are designed by engineers as a predefined set of rules, but have we addressed the question of what happens if we let the network come up with its own MAC protocol? Could it be better than a human-designed one?
In simple terms, we let each of the network nodes, the user equipments (UEs) and the base stations (BSs), be a RL agent that can send control messages to one another while also having to deliver data through the network. Then, the nodes can learn how to use the control messages to coordinate themselves in order to deliver the uplink data, effectively emerging their own protocol. This post is based on [1].
1. Introduction
A MAC protocol is a set of rules that allow the network nodes to communicate with one another. It regulates the usage of the wireless channel through two policies, the signaling policy and the channel access policy. The signaling policy is represented by the control plane, it determines the information that should be sent through the control channels and what the received information means. The channel access policy determines how the nodes can share a communication channel and it is represented by the data plane, as it determines when data can be transmitted through the shared channel. Figure 1 gives an example of a MAC protocol allowing two UEs to send data to the BS.
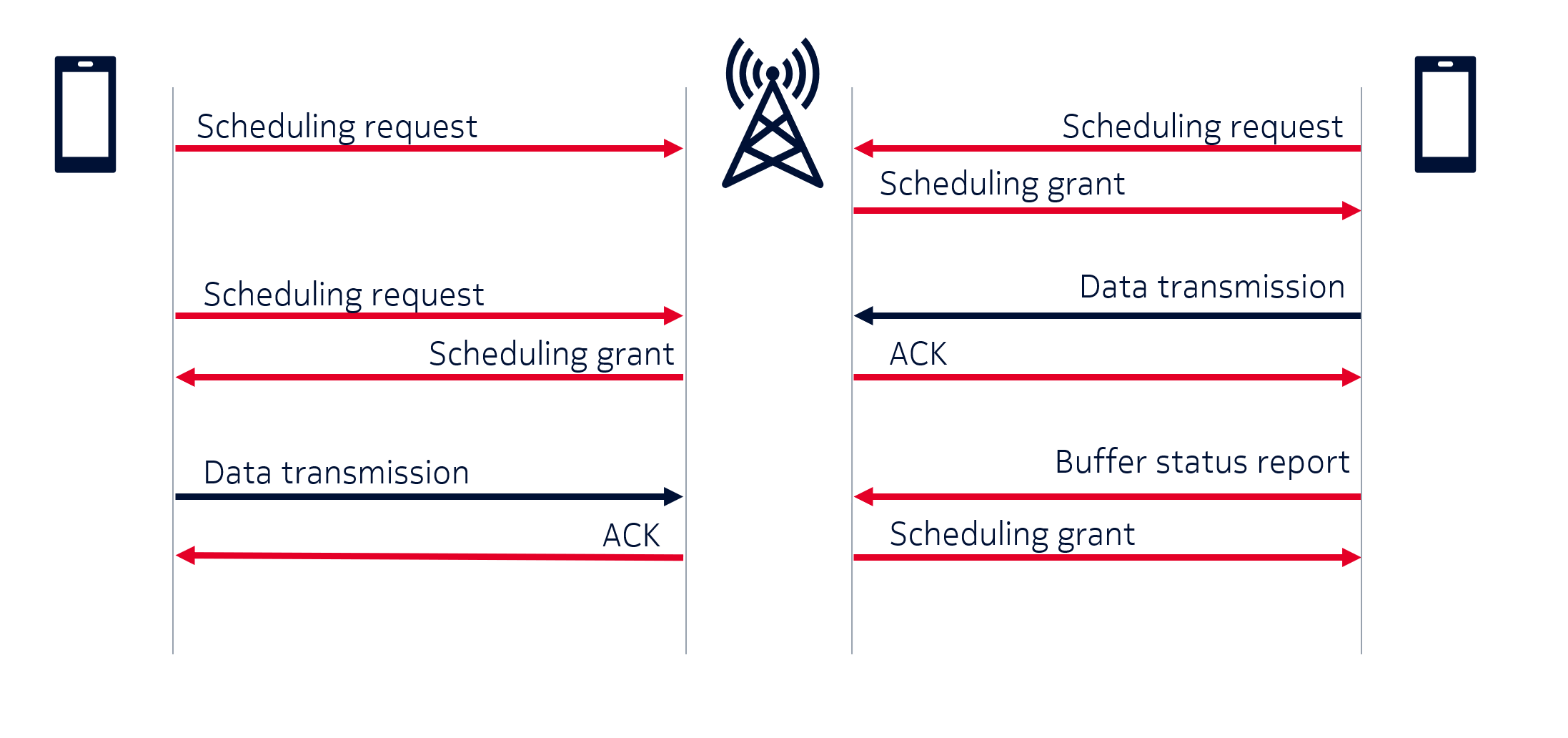
Most of the machine learning (ML) applications to MAC protocols have been for new channel access policies. Our proposal is to use ML for the nodes to learn both the signaling policy (control information) and the channel access policy, in order to come up with their own version of Fig. 1, that is, what to send through the control channel, the meaning of the control messages and how to use this information to send data across the shared channel. To do this we will use MARL augmented with communication.
2. Multi-Agent Reinforcement Learning
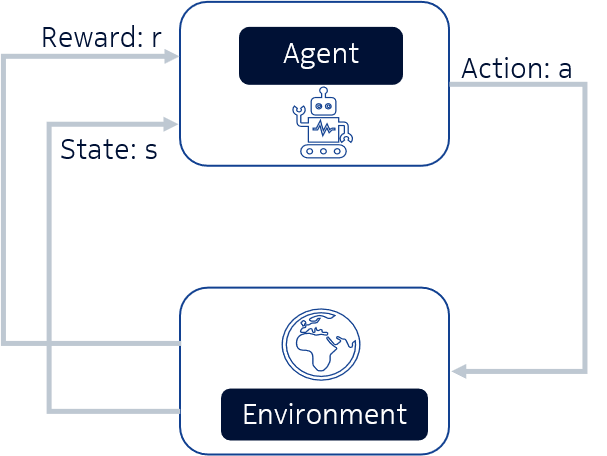
Reinforcement learning (RL) is an area of ML that aims to find the best behaviour for an agent interacting with a dynamic environment in order to maximize a notion of accumulated reward. In RL, the agent interacts with the environment by taking actions and it can observe the state of the environment in order to obtain information to guide its policy. The policy is a function representing the behaviour of the agent as it maps the perceived state of the environment for the action to be taken.
The procedure from the point of view of the agent can be simplified as:
- Select and take action.
- Observe the state transition and the received reward.
- Update the policy or the value function.
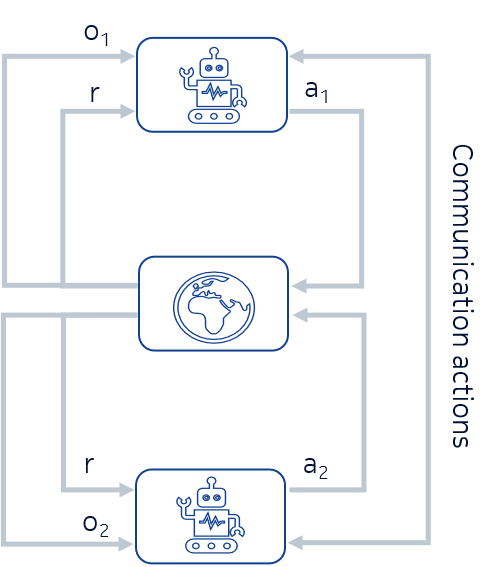
In MARL, however, we have multiple agents interacting with the environment. Since we are looking for cooperative behaviours, we are interested in partial observable environments, modelled as a partial observable Markov decision problems (POMDPs). In this case, the agent does not have access to the full state of the environment, because if the agent has all the information needed to guide its actions it does not need to cooperate in order to solve the problem. In this work, we help the agents cooperate by having a single team reward and also allowing the agents to communicate by taking communication actions. This is shown in Figure 3.
One of the main issues of MARL is the non-stationarity. For example, in Figure 3 the agent 1 perceives agent 2 as part of the environment and whenever agent 2 updates its policy it seems as if, from the agent’s 1 point of view, the model of the environment changed. This is due to the fact that the environment transition depends on the actions of both agents, besides the environment state. The algorithm we use in this work, multi-agent deep deterministic policy gradient (MADDPG), tries do address this issue.
2.1 MADDPG
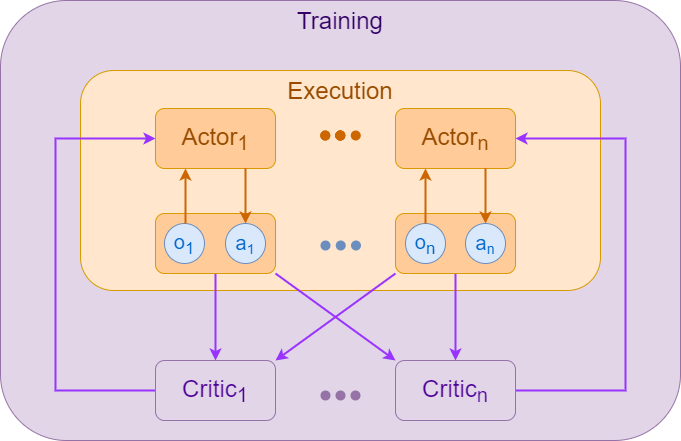
In the MADDPG, the framework of the centralized training and decentralized execution (CTDE) is used in order to address the non-stationarity issue. The algorithm follows the actor-critic architecture, where each agent has an actor network representing the policy and a critic network representing a value function:
- The actor network receives the state and outputs the action to be taken. It is a function approximation for the policy.
- The critic network receives the state and the action and outputs a real value representing how good is to take that action in that state in terms of future expected reward. It is a function approximation for the action-value function.
In the MADDPG, each agent has its own actor network, depending only of its own observation. During execution, only the actor network is needed. However, during training, each agent has a centralized critic and it receives the observations and actions of all agents in the system. The intuition behind this is that, if we know the action taken by all agents, the model of the environment is stationary even as the policies change.
3. System Model
Now we have to model our problem. First let’s look at the transmission task from the wireless system’s point of view of the before modelling it as a MARL problem.
The problem we are tackling is a multi-access uplink transmission scenario. We consider a single cell with a BS serving 2 UEs according to a temporal division multiple access (TDMA) scheme, with the UEs having to transmit packets to the BS. The BS and UEs can exchange information using control messages that are transmitted through a dedicated error-free control channel. The channel for the uplink data transmission is modelled as a packet erasure channel, where a packet is incorrectly received with a probability given by the block error rate (BLER). The UEs need to manage their transmission buffer by deciding when to transmit a packet and when to delete the packet from the buffer (it can only transmit the next packet after it has deleted the current one). This is shown in Figure 5:
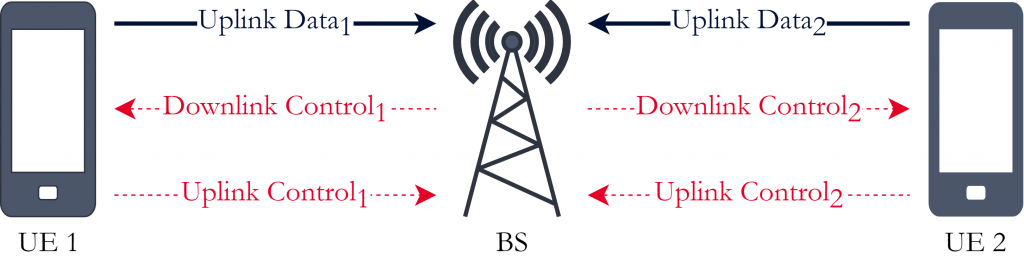
For model this as MARL problem that we need to decide the observations, the actions and the reward for:
- Observations:
- BS: Channel status (idle, busy or reception from UE n).
- UE: Number of packets in the transmission buffer.
- Environment actions (only the UEs can transmit in this task, so it is only defined for the UEs):
- Do nothing.
- Transmit the oldest packet in the buffer.
- Delete the oldest packet in the buffer.
- Reward:
- -3 if an UE deleted a packet that was not yet received by the BS.
- +3 if a new packet was received by the BS.
- -1 otherwise.
The agents also need to take their communication action, we assume that the number of communication actions for the downlink (DL) is three and for the uplink (UL) is two. These communication actions have no prior meaning and the agents have to agree on their meaning as they learn how to use it. The input of the actor network and also the observation used in the critic, which we call agent state, is a concatenation of the current observation and messages it has received, with the actions it has taken and some of the previous information (observation, action and messages).
4. Results
Tables 1 and 2 show some of the simulation parameters for the system and training algorithm.
| Parameter | Value |
|---|---|
| Number of UEs | 2 |
| Number of packets to transmit | [1, 2] |
| Initial buffer | Empty |
| Packet arrival probability | 0.5 |
| BLER | [10-1, 10-2, 10-3, 10-4] |
| UL vocabulary size | 2 |
| DL vocabulary size | 3 |
| Max. duration of episode in TTIs | 24 |
| History size | 3 |
| Parameter | Value |
|---|---|
| Batch size | 1024 |
| Update interval in TTIs | 96 |
| Learning rate | 10-3 |
| Discount factor | 0.99 |
In Figures 6 and 7, we compare the MADDPG solution with the DDPG, i.e. local critic instead of a centralized one, and a contention-free baseline. The performance is evaluated in terms of goodput, defined as the total number of packets received by the BS divided by the number of TTIs taken to finish the transmission task, the goodput does not consider retransmissions.
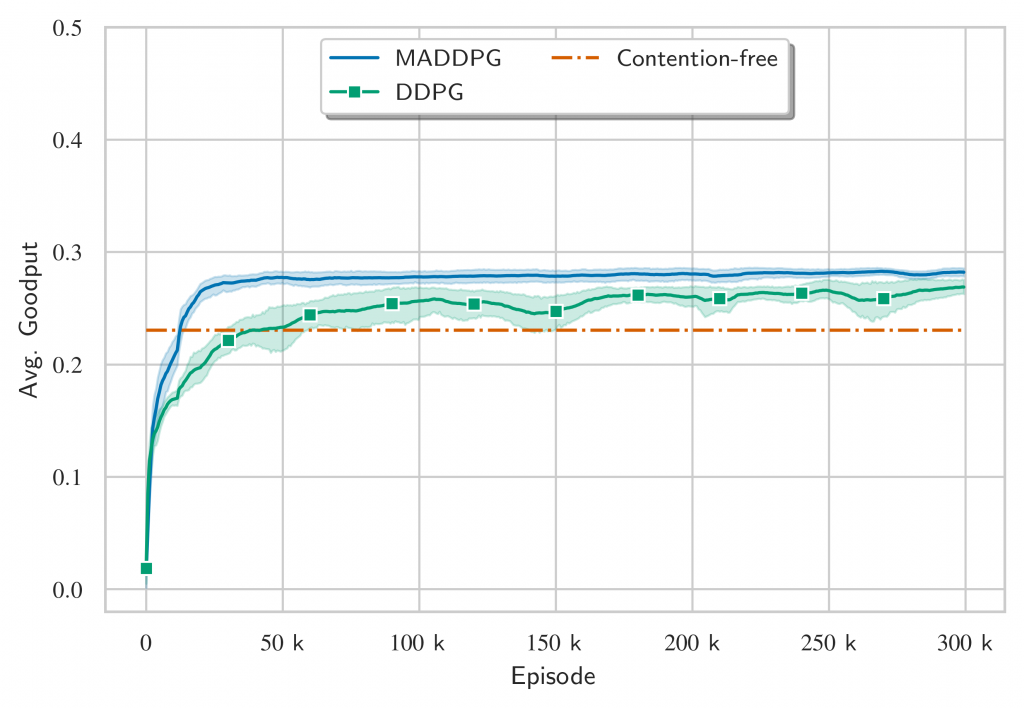
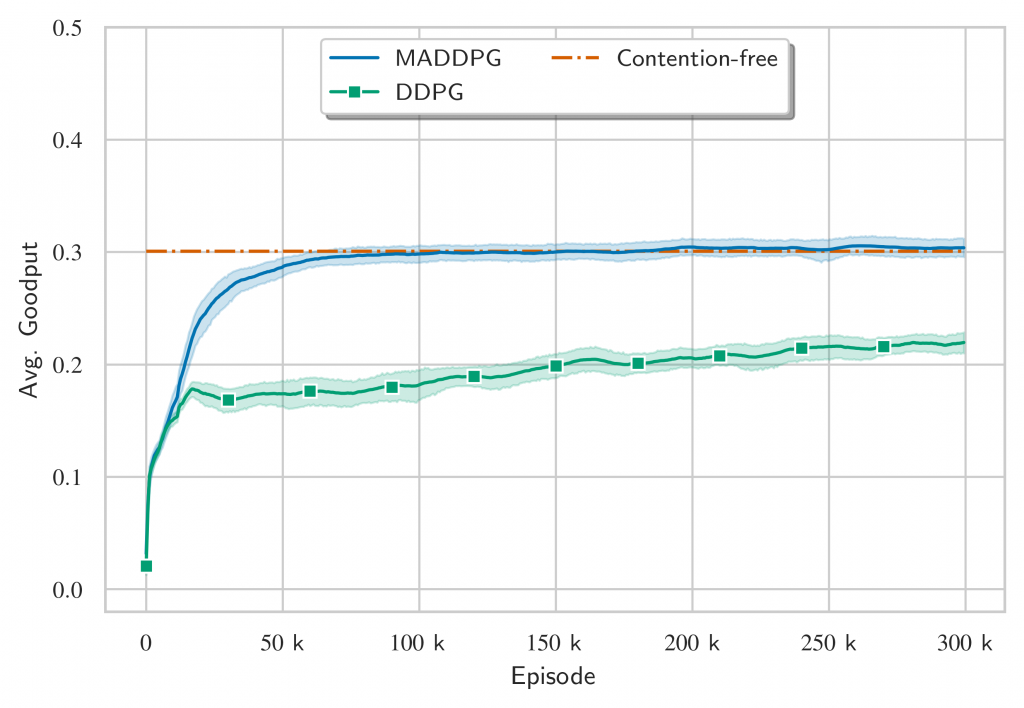
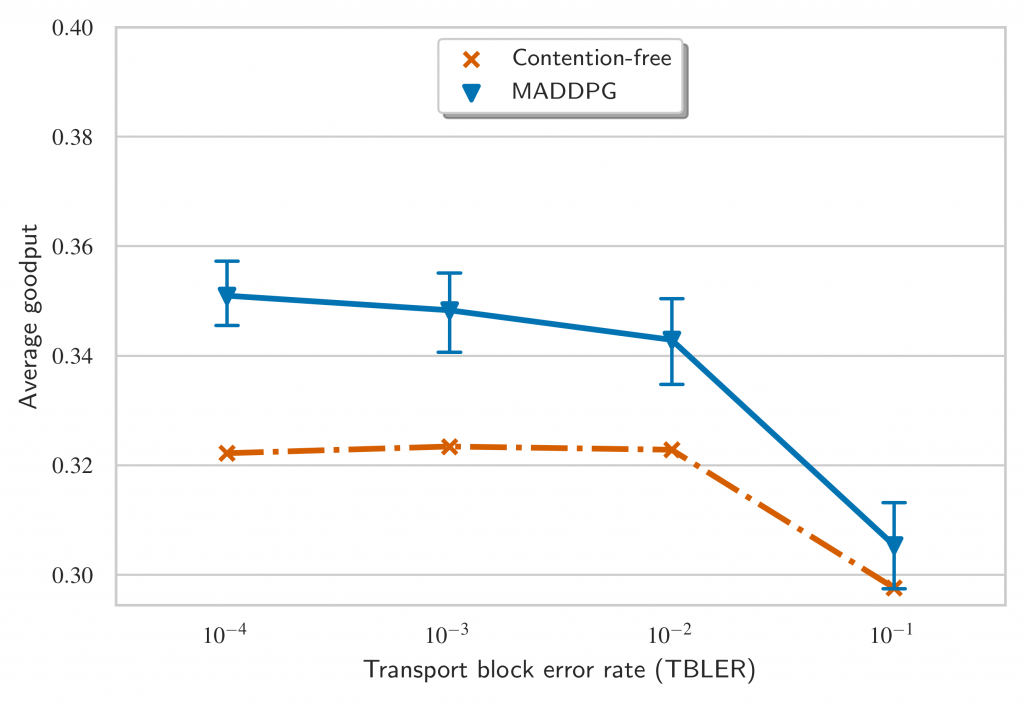
The results above show that the protocols emerged by the MADDPG have superior performance than the contention-based baseline. But what happens if we compare across different BLERs? This is question is answered in Figure 8 and it shows that the MADDPG can emerge a protocol tailored to low BLER regimes that performs better than a general-purpose one.
5. Conclusion
In this article, we answered the following questions:
- Can we use Multi-Agent Deep Reinforcement Learning to learn a signalling policy?
- How does the performance compare with a standard baseline?
- Can this framework produce a protocol tailored for different BLER regimes?
But other questions remain. How does this framework fares on more complex problems, such as channel-dependent scheduling, different use cases (URLLC) and more complex set of actions? To tackle this, our intuition tells that we need a larger vocabulary size, since more information is needed. Besides this, different rewards may be needed for different use-cases.
6. References
[1] Mota, Mateus P., et al. “The Emergence of Wireless MAC Protocols with Multi-Agent Reinforcement Learning” arXiv preprint arXiv:2108.07144 (2021). Link
[2] Lowe, Ryan, et al. “Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments.” Advances in Neural Information Processing Systems 30 (2017): 6379-6390. Preprint available on arxiv
[3] Foerster, Jakob N., et al. “Learning to communicate with deep multi-agent reinforcement learning.” arXiv preprFoerster, Jakob, et al. “Learning to Communicate with Deep Multi-Agent Reinforcement Learning.” Advances in Neural Information Processing Systems 29 (2016): 2137-2145. Preprint Available on arXiv